
该论文发表于IEEE Transactions on Information Forensics and Security (中科院一区,IF=6.3),题目为《Attention BLSTM-Based Temporal-Spatial Vein Transformer for Multi-View Finger-Vein Recognition》。重庆工商大学计算机科学与信息工程学院的教授秦华锋为此文第一作者。重庆大学计算机学院的教授李延涛为此文的通讯作者。
论文链接:https://ieeexplore.ieee.org/document/10695117
论文概要
由于其良好的隐私保护和高度的安全性,指静脉生物识别技术近年来受到广泛关注。尽管该领域已取得显著进展,但大多数现有方法仍主要依赖于从三维静脉血管投影到二维(2D)图像上的单视角图像中提取特征。然而,单视角的识别容易受到手指位置变化(尤其是由于手指旋转造成的)影响,进而降低识别性能。为了解决这一挑战,本文提出了一种基于注意力双向LSTM的时空静脉Transformer模型——ABLSTM-TSVT,用于多视角指静脉识别。首先,在LSTM中引入注意力机制,构建了注意力LSTM以提取时序特征。在此基础上,进一步引入了一个局部注意力模块,该模块能够学习多视角图像中一个图像块(token)与其邻近图像块之间的时间依赖关系,并与注意力LSTM融合形成时序注意力模块。其次,设计了空间注意力模块,用于捕捉单张图像中各图像块之间的空间依赖关系。最后,通过融合时序注意力模块与空间注意力模块,构建了时空Transformer模型,有效地表征多视角图像的特征表示。在两个多视角数据集上的实验结果表明,本文方法在提升身份识别准确率和减少静脉分类器验证误差方面优于现有先进方法。
研究背景
指静脉识别仍然是一项具有挑战性的任务,因为多种因素会导致图像质量下降,这些因素可大致分为两类:一是外部因素,如环境光照、温度变化以及光散射等,这些会在图像中引入噪声、不规则阴影,甚至造成静脉图案缺失;二是内部因素,如用户的操作行为,可能会引起图像的旋转和平移。在图像采集过程中,用户的手指可能沿 X、Y、Z 三个轴发生平移与旋转:其中,X 和 Y 轴方向的平移会影响图像中手指区域的位置,Z 轴方向的平移则会改变其尺度;而沿这三个轴的旋转——即滚转、俯仰和偏航——会以不同方式影响最终图像。具体而言,偏航可能使手指在图像中产生旋转,俯仰可能导致手指变形从而造成静脉结构扭曲,尤其值得注意的是,滚转会改变三维血管结构在二维图像上的投影角度,尤其在大角度时,不同视角下同一手指采集到的静脉图像差异会变得十分显著,最终导致注册图像与测试图像之间的不匹配,从而影响识别性能。由于大多数用户对静脉识别缺乏专业知识,在图像采集时可能错误地放置手指,进一步加剧了采集图像之间的差异。而无接触式采集系统则往往带来更多的变化,包括旋转、平移和尺度变化。
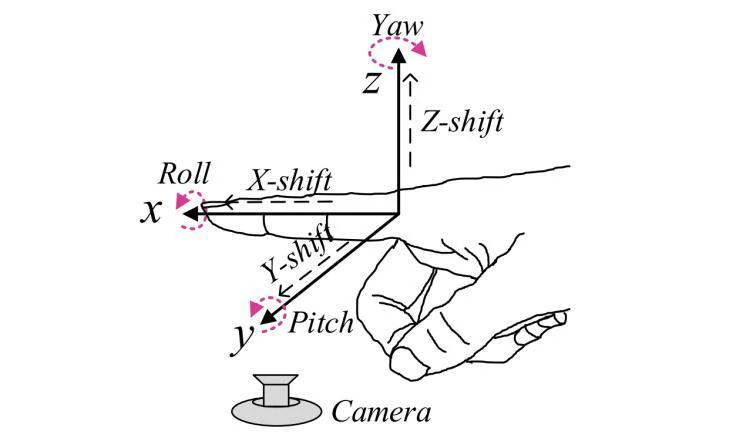
研究方法
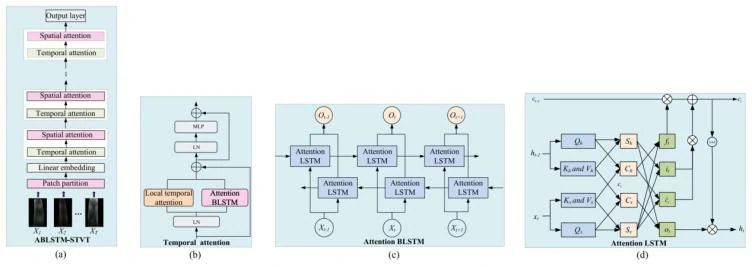
基于注意力机制的BLSTM时空静脉Transformer(即ABLSTM-TSVT)由空间注意力模块、时间注意力模块和嵌入层组成,如图2(a)所示。首先,对多视角指静脉图像序列中的每一幅图像进行卷积处理,将其划分为 N=196 个图像块(patch),每个图像块随后被转换为一个嵌入向量。接着,这些嵌入向量被送入时间注意力模块(如图2(b)所示),以学习多视角图像之间的时间依赖关系。时间注意力模块的输出作为空间注意力模块的输入,用于提取图像内部各图像块之间的空间相关性。通过这种交互式的处理流程,模型能够有效提取并优化图像序列中的特征,为后续的分类任务提供支持。
序列嵌入

时间注意力
时间关系信息是多视角分类中的关键特征。为了有效地捕捉这种时间信息,引入了一个时间注意力模块,该模块由局部时间注意力模块和注意力双向 LSTM(BLSTM)组成。
局部时间注意力

注意力 BLSTM

LSTM 架构包含四个模块:遗忘门、输入门、记忆单元和输出门。其中,遗忘门 决定从记忆单元中舍弃哪些信息。该决策由一个 Sigmoid 激活函数控制,如公式(7)所示:
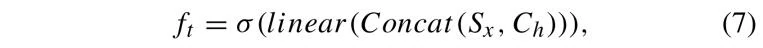
其中,σ 表示 Sigmoid 函数,linear 表示线性映射函数,Concat 表示向量拼接操作。输入门 负责处理当前输入,如公式 (8) 和公式 (9) 所示:
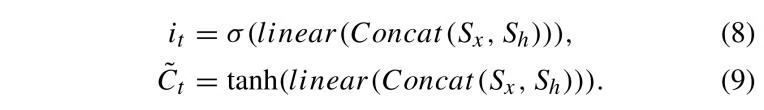
记忆单元被设计用于缓解梯度消失问题,从而有助于模型的训练,特别适用于包含长序列的数据集。记忆单元的输出由公式 (10) 给出:
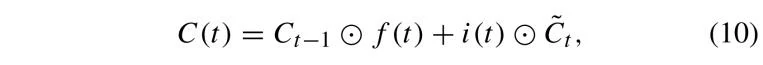
其中,⊙ 表示 Hadamard(元素级)乘法运算符。
与前两个门控机制类似,输出门通过公式 (12) 计算:
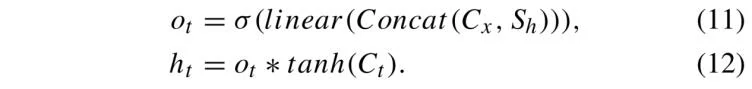
BLSTM 是 RNN 的一种变体,增强了标准 LSTM 在处理长期依赖关系方面的能力。为了进一步提升性能,论文中提出了注意力 BLSTM(Attention BLSTM),该结构在前向和后向两个方向中引入注意力机制,从而实现信息的同步提取,如图 2(c) 所示。在 Forward 层中,注意力 LSTM 按顺序从第 1 个 token 处理到第 T 个 token,逐步获取前向隐藏层的输出。相反,在 Backward 过程中,注意力 LSTM 按相反顺序从第 T 个 token 处理到第 1 个 token,逐步获取后向隐藏层的输出。六个权重 V、V′、U、U′、Z 和 Z′ 被迭代使用,以通过公式 (13)、(14) 和 (15) 融合前向和后向层的输出。
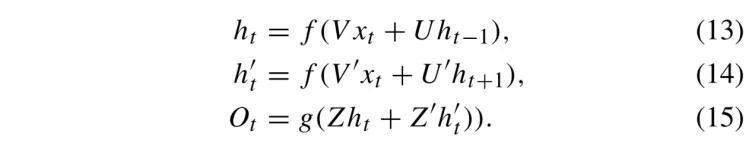

空间注意力

对比实验
闭集场景中的识别性能
为了评估所提方法的有效性,论文中将 ABLSTM-TSVT 与代表性的 2D 单视角识别方法,以及 3D 多视角识别方法进行比较。常用的均衡误差率(EER)用于评估性能,它是虚假接受率(FAR)等于虚假拒绝率(FRR)时的点。此外,采用了TAR@FAR = 0.1%,其中TAR = 正确接受的合法用户数 / 所有合法用户数,FAR = 错误接受的非法用户数 / 所有非法用户数,TAR@FAR = 0.1%是指FAR 限制在 0.1% 的时候,系统对合法用户的接受率是多少。表 一、二、三、四 和 五 展示了在两个数据集上各种方法的识别准确率。
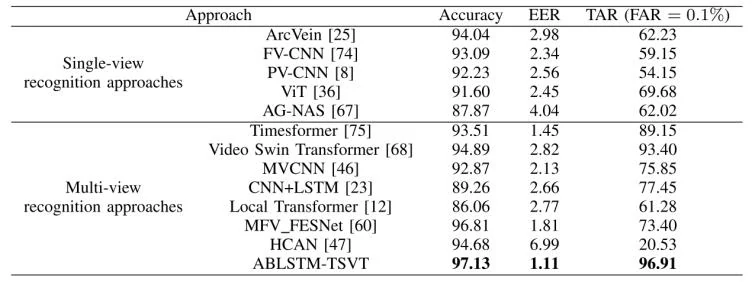
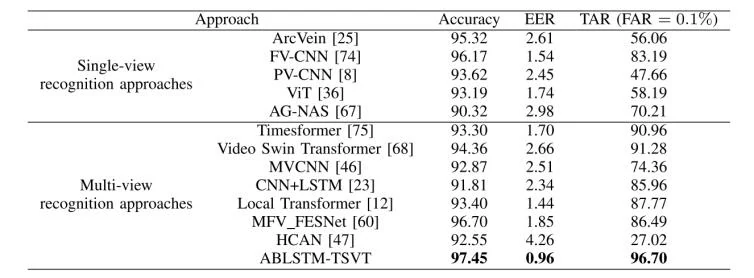
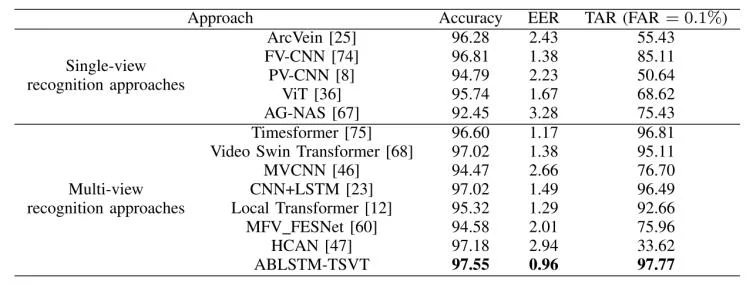
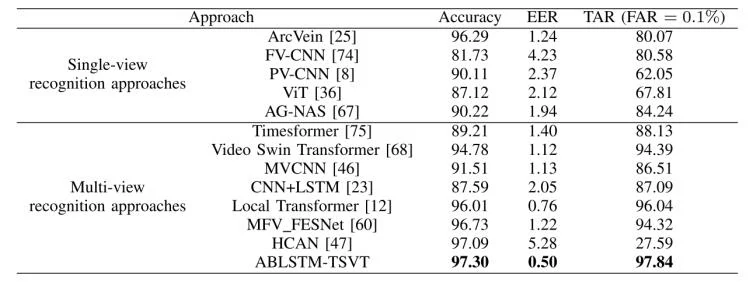
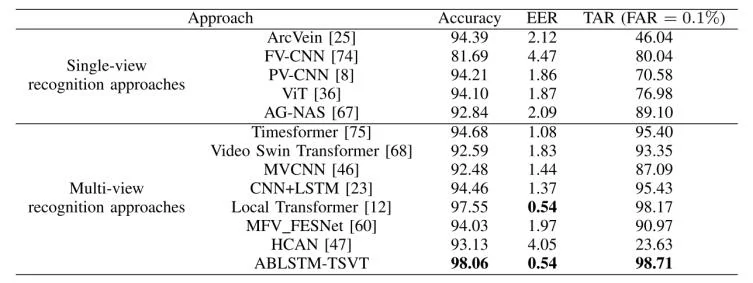
具体而言,对于数据集 CTBU,所提出方法达到了 97.55% 的识别准确率和 0.96% 的 EER;对于数据集 LFMB-3DFB,则分别达到了 98.06% 的识别准确率和 0.54% 的 EER。特别地,在 FAR = 0.1% 时,所提出方法在数据集 CTBU上达到了 97.77% 的 TAR,在数据集 LFMB-3DFB上达到了 98.71% 的 TAR。
开集场景中的识别性能
实验结果如表六所示,表明所提出方法在两个数据集上都保持了高识别性能,即使测试集中包含了来自额外类别的样本。该方法能够有效识别并拒绝冒名顶替者,从而展示了所提出的指静脉识别系统在实际应用中的有效性。此外,表七中的验证结果表明,即使测试集仅包含新类别,该方法仍然能够取得令人满意的验证性能。这些结果表明,该方法非常适合实际的验证场景。


消融实验
首先,论文中使用标准的自注意力模块来捕捉空间依赖性,该方案作为基线(baseline)。随后,引入邻域时间注意力来学习多视角图像间的时间依赖性,该方案被记作 (baseline)+ 局部时间注意力。类似地,将局部时间注意力替换为注意力BLSTM模块,此方案记作 (baseline)+ BLSTM注意力。最后,同时结合局部时间注意力模块与注意力BLSTM模块提取时间信息,同时保留标准的空间自注意力机制,用于空间特征学习,构成 ABLSTM-TSVT模型(baseline+BLSTM注意力 + 局部时间注意力)。
各种方法在两个数据集上的识别结果展示在表八、九、十、十一与十二中。实验结果表明,引入的局部时间注意力模块与注意力BLSTM模块能显著提升识别性能。





结论
本文提出了一种基于注意力双向LSTM的时空静脉Transformer(ABLSTM-TSVT),用于多视角静脉图像识别。ABLSTM-TSVT由多个时空模块组成,每个模块包括一个时间模块和一个空间模块。时间模块能够有效学习序列中多视角指静脉图像之间的鲁棒时间特征依赖关系,而空间模块则用于捕捉图像内部各个图像块之间的空间依赖。在两个多视角静脉数据集上的综合实验结果表明,ABLSTM-TSVT优于当前的2D/3D静脉识别方法,在多视角三维指静脉识别任务中实现了最高的识别准确率。多视角三维指静脉识别的研究热度不断提升,原因在于其能够提供更具区分性的信息,并缓解由手指滚动带来的图像不匹配问题。
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=16947