本篇学习报告介绍2022年2月发表于中科院一区期刊IEEE Journal of Biomedical and Health Informatics的论文“Investigating of Deaf Emotion Cognition Pattern By EEG and Facial Expression Combination”,作者Yang Y, Gao Q, Song Y等来自天津工业大学。
背景
本论文主要研究了对聋人进行情感识别的问题。与一般人相比,聋人在情感感知方面可能有所不同,因为他们缺乏通过听觉获取情感信息的渠道。因此,本研究旨在利用深度信念网络(DBN)将脑电信号和面部表情相结合,进行情感分类。
脑电图(EEG),许多心理生理学研究指出情绪与大脑皮层的神经细胞聚集电活动有关。此外,与侵入性测量方法(传感器必须放置在头皮下,例如脑皮层电图和深度电极)相比,基于EEG的设备更易于佩戴和携带,从而使得实时情绪识别(如睡眠评分、疲劳驾驶和工作负荷计算)成为可能。
面部表情(FE),作为一种具有非接触的自然特征,人脸因其极高的可区分性、易用性以及稳定性被广泛应用于各种识别场景中。
方法与模型
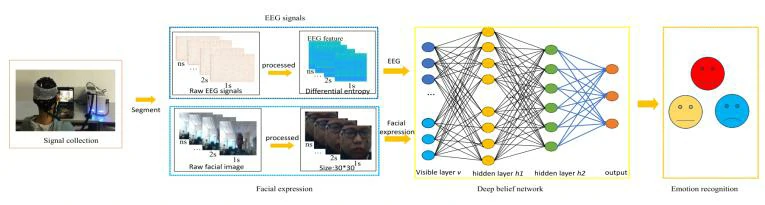
论文提出了一种基于深度信念网络(DBN)的方法,将脑电信号和面部表情的特征进行融合,用于聋人的情感分类。首先,收集了15名聋人在观看不同情感影片时的脑电信号和面部表情图像。接着对脑电信号进行预处理,提取了不同频段的差分熵(DE)特征,得到了310维的特征向量。同时,从面部视频中提取第一帧图像,并选择部分面部表情,将图像调整为30*30的灰度图像。然后将脑电信号和面部表情特征融合为一个特征向量,作为DBN的输入。最后使用DBN进行情感分类。
深度信念网络(DBN)是一个具有深度结构的概率生成模型,由一个受限玻尔兹曼机(RBM)组成。如图1所示,RBM只有两层神经元,一层称为可见层,由可见单元组成,用于输入训练数据。另一层称为隐藏层,由隐藏单元组成,用作特征检测器。输入数据对应于可见层,提取的特征可以被看作是隐藏层。模型在同一层上没有内部连接。
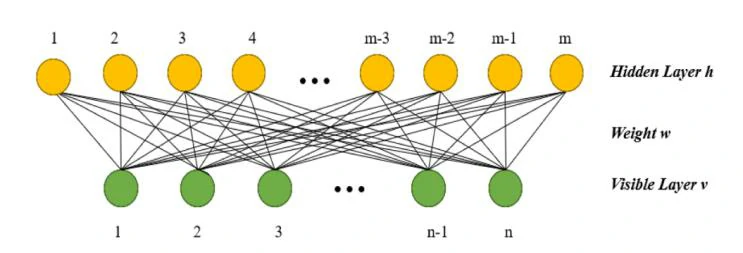
由于RBM是一个二分图,所以在层内没有边连接,因此给定可见层节点的值,隐藏层的激活是有条件独立的。同样地,给定隐藏层的值,可见层节点的激活状态也是有条件独立的。因此,可见层v对于隐藏层h的条件概率如下:
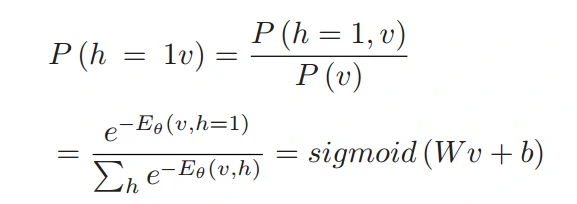
由于RBM的对称结构,可以得到隐藏层对于可见层的条件概率如下:
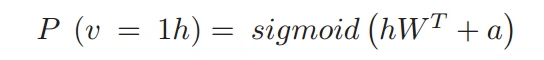
由于RBM层内没有连接,同一层中的变量也是彼此独立的,可以得到以下公式:
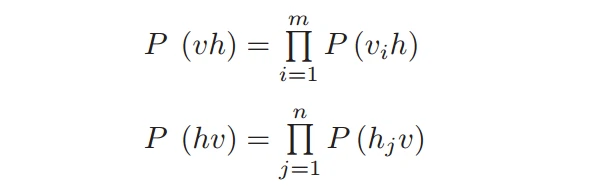
RBM的训练目的是将原始数据的分布保持在最大程度上,并且最大似然估计是为了最大化P(v)。使用对数似然函数,公式如下:
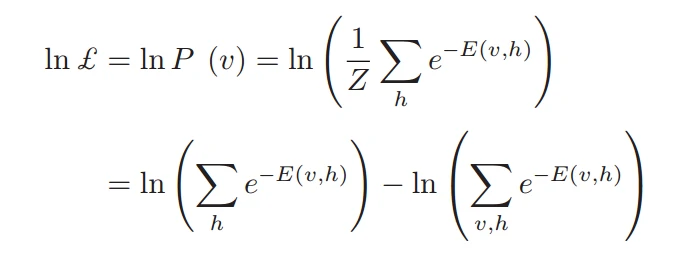
实验设计
为了唤起聋人受试者的特定情感,本文使用了三种情感电影片段(由心理学家挑选)。当聋人受试者观看这些电影片段时,本文采集了他们的脑电图信号和面部表。脑电图信号和面部表情图像均通过一个长度为1秒、不重叠的滑动窗口进行分割。从脑电图信号和面部视频中提取了差分熵特征和面部表情特征。然后,这两种类型的特征被输入到提出的深度信念网络(DBN)中。实验的总体框架如图2所示。
实验结果与分析
基于EEG的分类

文章比较了EEG三种常用特征(功率谱、小波熵和差分熵)在聋人情感识别中的性能。使用了四个指标(准确度、宏平均召回率、宏平均精确度和F1)来评估这三种特征的分类性能。此外,还考虑了时间复杂度。如表1所示,结果显示差分熵特征在情感分类中表现出色。并且差分熵所需的时间明显少于其他两种特征。因此,之后的整个实验中采用了差分熵特征。
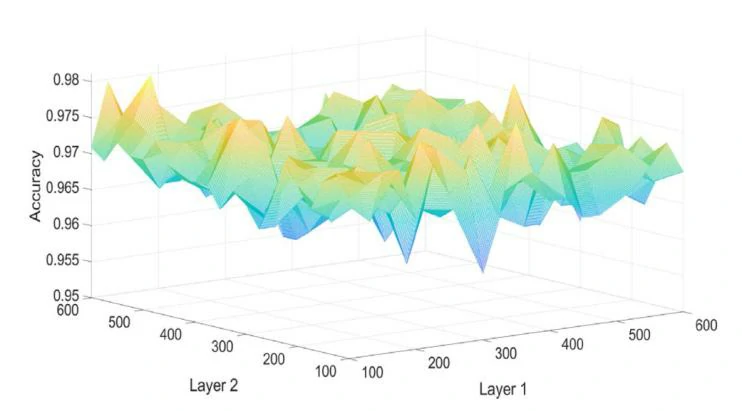
为了获得DBN中两个隐藏层的良好预训练参数数量,本文进行了比较实验。第一个隐藏层的神经元数量从100到500选择,第二层的神经元数量也从100到500选择,两层的步长为25。不同神经元数量的DBN性能如图3所示。从结果可以看出,当第一层的神经元数量约为100,第二层的神经元数量约为300时,DBN表现出色。
不同分类器的平均准确性、召回率、精确度、F1值和时间成本以及与DBN的p值如表2所示。实验结果表明,DBN在准确性、召回率、精确度和F1值方面均优于SVM、KNN、NB、RF、DT和DNN,其准确性约为99.31%。此外,还考虑了计算时间,结果显示所提出的DBN需要较长的训练时间(577.39秒),但DBN的测试时间(0.59秒)低于SVM(1.49秒)和DNN(0.62秒)。

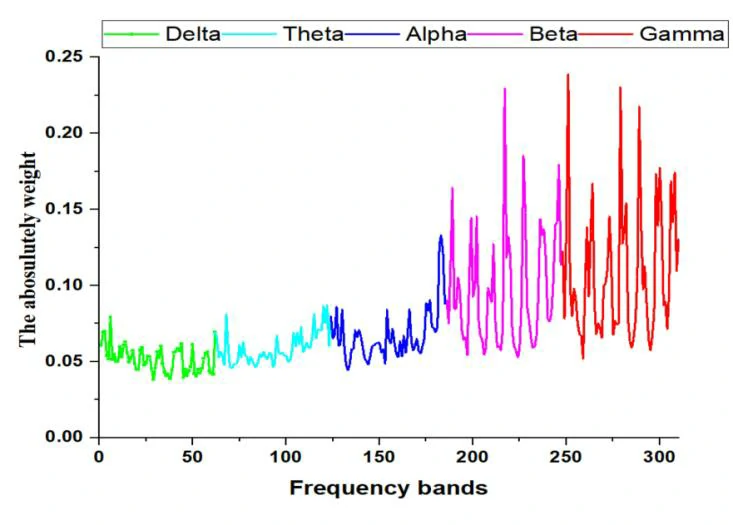
为了进一步分析输入特征向量与情感之间的关系,本文提取了DBN中15名聋人受试者的平均权重,结果如图4所示,对于δ、θ和α波段,其权重值小于β、γ波段。因此,本文对每个频段分别进行了情感分类,以验证情感EEG在高频段中的活动性。
在五个频带中七种分类器的分类性能实验结果如图5所示。从五个EEG节律频带中,结果显示γ波和β波的分类准确性比α、θ和δ波高,这表明γ波与聋人情感密切相关,β波也可以粗略反映聋人情感的变化。此外,结果还显示,将五个节律波段合并为一个特征向量时,采用SVM、KNN、NB、RF和DT等分类方法会导致性能下降。这可能表明在融合多频段信息时可能存在大量冗余信息,这将影响传统机器学习方法对情感分类的准确性。然而,所提出的DBN可以在一定程度上避免特征冗余的影响,并提高分类性能。
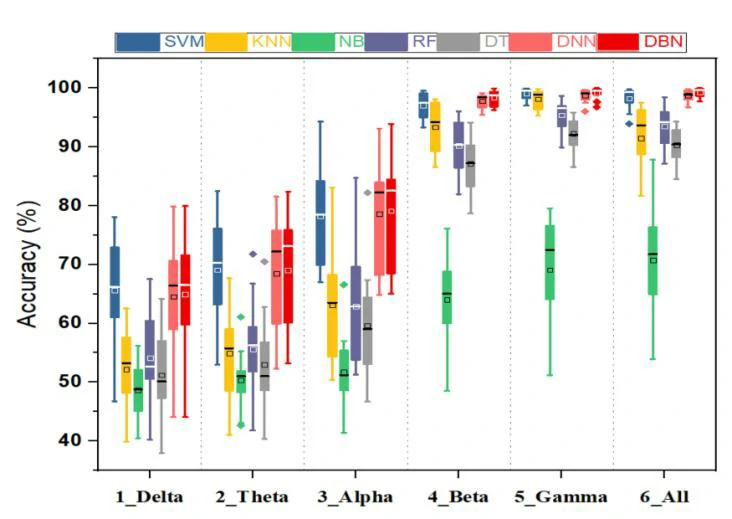
为了验证所收集的聋人脑电信号在与SEED数据集相同范式下的质量,本文在SEED数据集中提取了DE特征,采用了SVM和DBN进行了10折交叉验证。从表3中可以看出,通过SVM,**聋人在相同范式和条件下的分类准确度比正常人高出10.44%**,这可能表明所收集的聋人脑电信号质量更高。此外结果显示,与SVM相比,DBN模型的分类准确度提高了5.72%。

基于面部表情的分类
本文使用DBN来研究微妙的表情变化。实验中使用笔记本收集了15名聋人受试者的面部视频。文章使用DLIB来减少与情感识别过程无关的背景信息的影响。所有面部样本的大小被设置为30∗30。
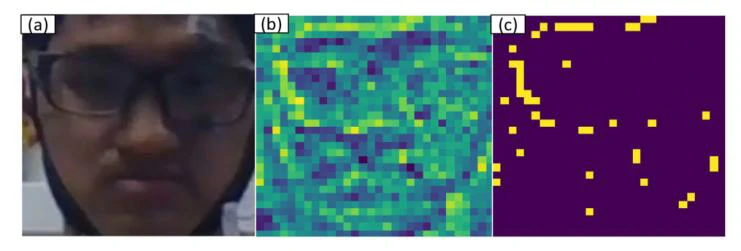
如图6所示,提取了15名聋人受试者的DBN权重,并对其绝对值进行了平均处理,以获得面部表情的关键位置。对聋人的面部表情特征的绝对权重进行了归一化,并按从大到小的顺序进行了排序,选择了前30个面部特征。从图8(c)可以看出,结果可能表明面部表情与眼睛周围的区域和眉毛密切相关。
基于EEG与面部表情特征融合的分类
本文从62个EEG通道中提取了62个差分熵(DE)特征,得到一个310维的特征向量。对于面部表情,使用DLIB的面部识别模型来定位面部表情图像,并将其调整为30x30的灰度图像。310维的DE特征和900维的灰度图像被合并成一个特征向量(1210维),作为输入传递给DBN。为了避免算法陷入局部最优解,批处理大小设置为200。
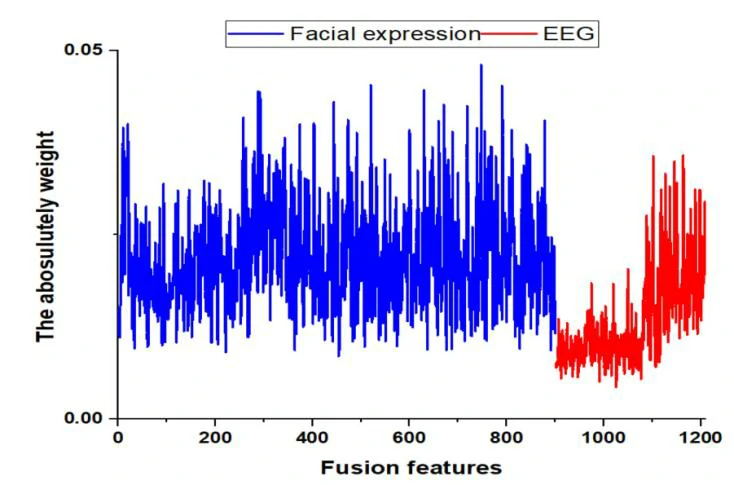
对于所有特征融合,分类准确率为98.35%,比面部表情情感识别高0.14%,比EEG情感识别低0.96%。多模态融合方法的分类准确度较低可能是由于特征冗余造成的。因此,本文计算了基于聋人面部表情和EEG融合特征的平均权重。从图7中可以看出,每种模态特征中都存在一些绝对权重较小的值,这可能导致特征冗余并影响情感分类的性能。
为了解决上述特征冗余问题,本文使用了DBN的最大权重来分析EEG情感通道和主要面部特征。对于十五名受试者的平均权重结果发现,主要的EEG电极是FP2、FP1、FT7、FPZ、F7、T8、F8、CB2、CB1、FT8、T7、TP8,这表明聋人的情感与前额叶、侧颞叶和枕叶相关。此外,本文选择了权重大的前30个面部表情特征(眼睛和眉毛周围的区域)。
本文在特征选择后对单一模态进行了情感分类。然后,更新后的30个面部特征和伽马波段中的12个主要EEG通道特征被合并为42维的融合向量用于情感识别。如表4所示,对于单一模态,在特征选择后,分类准确率分别为99.26%(伽马波段中的12个主要EEG通道)和99.57%(前30个面部表情特征)。此外,不同方法之间进行了成对样本t检验,结果p < 0.05。此方法的时间复杂度也得到了降低。

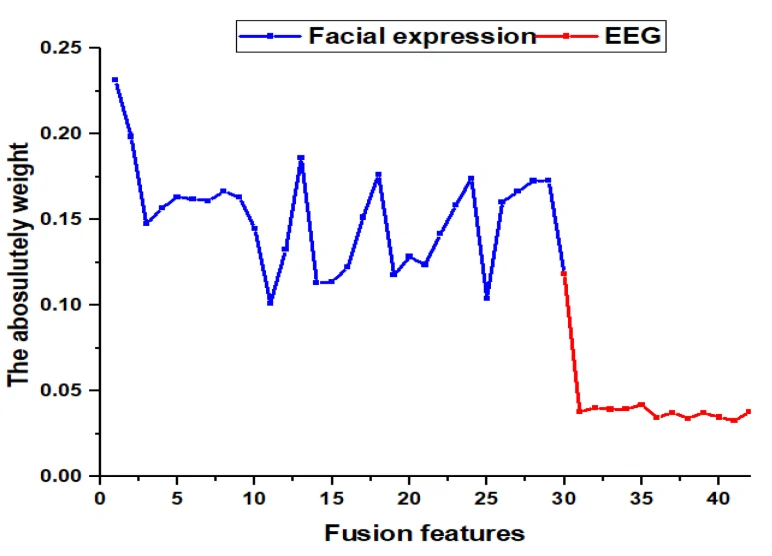
为了进一步分析所选择的融合特征,图8显示了更新后融合特征的权重分析。可以看到,面部表情特征的权重明显比EEG特征大。
总结
本研究将深度信念网络(DBN)模型应用于特征级别上融合脑电信号和面部表情。将两种模态的特征融合为DBN的输入,以对三种情感进行分类(积极、中性和消极)。分类准确率为98.35%,比面部表情情感识别高0.14%,比脑电情感识别低0.96%。
为了减少融合特征的维度,文章使用了权重分析来选择与情感密切相关的特征信息。选择了包括FP2、FP1、FT7、FPZ、F7、T8、F8、CB2、CB1、FT8、T7和TP8在伽马波段的12个主要脑电通道,以及前额、眼睛和眉毛周围的前30个面部表情特征来进行情感分类。结果显示,在聋人情感识别中,通过特征选择,分类准确率达到了99.92%。
根据本研究推测聋人的情感感知模式可能与三种原因相关。一是聋人缺乏获得情感信息的途径,但他们对情感的感知并没有改变,可能会比正常人更直接地定义情感类别。在相同实验范式下,通过脑电信号,本研究发现聋人在情感分类方面明显优于SEED数据库中的正常人。二是由于听力丧失,聋人会利用视觉来补充听觉信息,使得聋人能更仔细地观察面部表情。主要的脑电信号通道可能表明了聋人的枕叶电极(CB1、CB2)也处于活跃状态,这个区域与人类的视觉处理密切相关。三是尽管聋人和正常人在情感表达区域上是相同的,但电极位置也存在差异。与此同时,聋人可能会比正常人更善于利用面部表情来表达情感。
但由于样本量较小以及未考虑性别因素等限制,本研究还存在一些潜在的改进空间。在未来的研究中,可以通过扩大样本量、引入更多的聋人参与实验等方式,进一步验证所提方法的有效性,并探索更多的情感识别方法,为聋人提供更好的情感交流和支持。本研究在未来也将使用迁移学习的多模态融合来开发一个跨受试者模型,从而实现从正常受试者到聋人的跨受试者情感分析,以探索更深层次的情感感知区域。
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=14320